Développement du logiciel Cartes & Données : évolutions, fiabilité, ergonomie, performances
Jérôme Barthelemy, directeur technique et responsable R&D du Groupe Articque, revient sur les travaux de développement du logiciel Cartes & Données et sur les optimisations qui lui sont apportées pour améliorer ses performances.

Développement de Cartes & Données,
logiciel de cartographie décisionnelle et de Géomarketing
« Cartes & Données est un logiciel dont la conception remonte à plus de vingt années. Le premier prototype, sur ordinateur NeXT, date de 1991. Depuis cette date, Cartes & Données a évolué, et nous en sommes aujourd’hui à la version 6 du logiciel, avec la version 6.1 dont la sortie est prévue au 15 octobre 2012. Il n’y a donc pas que les logiciels Open Source qui soient pérennes !
Le sujet de cet article, et celui d’autres qui suivront, est dévolu à l’une des conditions de cette pérennité : l’activité de recherche et développement. Il ne sera donc pas question ici des autres conditions, économiques, commerciales et humaines qui sont tout aussi nécessaires. Cet article parle de l’activité de recherche et développement assurée par une équipe de développeurs de talent, qui mettent leur compétence et leur énergie à améliorer le logiciel, le faire évoluer, le corriger : le faire vivre.
Bien entendu, une grande partie de notre activité de développement est dévolue aux évolutions nécessaires de Cartes & Données, son adaptation aux nouvelles normes comme le HTML5, ou les standards de l’Open Geospatial Consortium, ou bien encore l’intégration de nouvelles méthodes statistiques ou de représentation. Mais une autre partie tout aussi importante de notre activité est un travail de fond visant à améliorer
Cartes & Données, du point de vue de sa fiabilité, de son ergonomie et de ses performances. Ce premier article porte plus précisément sur l’amélioration des performances, et en particulier sur l’exploitation des architectures multicœurs dites « architectures parallèles ».
Améliorer les performances : paralléliser
L’amélioration des performances des logiciels, depuis l’avènement de la micro-informatique, repose en premier lieu sur l’amélioration des performances du matériel : cadence des processeurs, capacité mémoire, temps d’accès aux ressources (mémoire vive et périphérique de stockage). On peut en première approximation dire que si la fréquence d’horloge double, et si les performances des autres périphériques s’améliorent dans les mêmes proportions, alors la vitesse d’exécution des logiciels doit doubler.
Toutefois, depuis un certain temps, les choses sont devenues plus compliquées. En effet, les fabricants de micro-processeurs n’arrivent plus à augmenter la fréquence d’horloge (en raison principalement de la chaleur dégagée qui devient trop importante).
Pour améliorer les performances, la nouvelle approche consiste à installer plusieurs unités d’exécution par processeur (on appelle cela les architectures multi-cœurs). Mais les gains en temps d’exécution ne sont plus automatiques. En effet, les logiciels qui n’ont pas été conçus pour tirer parti des ces architectures ne gagnent pas en vitesse. On pourra seulement exécuter plus de logiciels en même temps, mais aucun de ces logiciels ne gagnera en temps d’exécution s’il n’a pas été conçu de manière adéquate.
C’est le cas de Cartes & Données, du moins jusqu’à la version en cours de livraison: il ne tirait pas parti des nouvelles architectures, et l’exécution d’un Organigramme de C&D prend approximativement le même temps sur une machine mono-cœur ou multi-cœurs. En effet, Cartes & Données n’exploite réellement que l’un des processeurs disponibles, ce que l’on peut facilement vérifier à l’aide du « moniteur de ressources » de Windows. Cet utilitaire présente notamment un graphique montrant le pourcentage d’utilisation des processeurs. Voici donc une capture d’écran du moniteur de ressources prise durant l’exécution d’un Organigramme de Cartes & Données (version 6.0.2075, de juillet 2012), sur une machine à 8 cœurs :
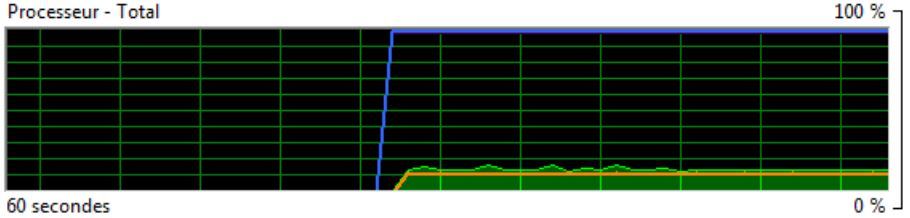
Utilisation du processeur par Cartes & Données 6.0.2075
L’utilisation du processeur par Cartes & Données est ici mesurée par le trait orange (à peine au dessus de 10%). On constate que Cartes & Données n’utilise qu’une très faible partie des ressources disponibles – en fait, environ 12,5%, ce qui correspond à 1/8ème de la ressource de calcul disponible – 1 seul processeur sur les 8 disponibles ! Notre objectif est donc de mieux utiliser la puissance de calcul disponible, d’utiliser tous les processeurs. Pour cela, il convient tout d’abord de définir la stratégie adéquate.
Notre stratégie : optimiser les modules gourmands en temps de calcul
Plusieurs stratégies pourraient s’appliquer en première analyse : par exemple, dans le cas de Cartes & Données, on pourrait imaginer d’exécuter des branches particulières de l’Organigramme en parallèle, c’est à dire de lancer l’exécution de modules en parallèle lorsqu’ils sont indépendants l’un de l’autre. Toutefois, cette stratégie ne nous a pas paru adéquate : en effet, Cartes & Données est un logiciel très gourmand en temps d’exécution dans la mesure où certaines opérations, par exemple les opérations de discrétisation, de maillage, d’agrégation ou d’interpolation sont intrinsèquement gourmandes en temps de calcul. Il est donc peu probable que le gain en temps d’exécution de cette première stratégie soit significatif: en effet, si l’on exécute en parallèle deux modules dont le premier met 1/10ème de seconde à s’exécuter, et le second met 10 secondes, le gain attendu sera de 1/10ème de seconde (soit 10 secondes au lieu de 10, 1). Cette première approche n’est donc pas une bonne approche.
Nous avons donc choisi une seconde approche : celle de se baser sur la structure interne des modules eux mêmes, qui, la plupart du temps, effectuent des calculs répétitifs sur beaucoup d’entités, en boucle. L’approche va consister à répartir chaque itération de ces boucles sur les différents processeurs. Le résultat, en termes d’utilisation de la puissance de calcul, peut être illustré en utilisant à nouveau le « moniteur de ressources » de Windows.
Voici une capture d’écran prise durant l’exécution d’un Organigramme de Cartes & Données, version 6.1, (sortie en octobre 2012), sur un processeur 8 cœurs :
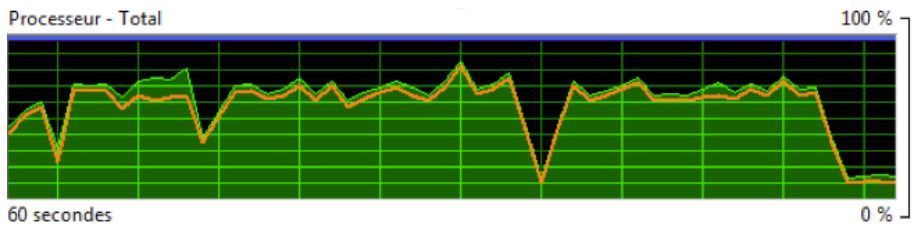
Utilisation du processeur par Cartes & Données 6.1
On constate, avec cette version, que l’utilisation de la puissance de calcul est passée de 12,5% à beaucoup plus de 50% (aux environs de 60 à 70%). Nous devons donc nous attendre à constater un gain en performances…
Les résultats
Nous avons donc mesuré les gains en performances. Pour cela, nous avons tout simplement exécuté deux versions du logiciel : la version 6.0.2075 de juillet 2012 (non parallélisée), et la version 6.1 d’octobre 2012 (parallélisée) sur la même machine et nous avons relevé les temps d’exécution de certains Organigrammes typiques, similaires à ceux que l’on trouve dans les exemples du logiciel : un exemple utilisant les modules grille et interpolation, et un autre exemple utilisant le module d’agrégation.

Nous avons mesuré le gain en performances sur une machine biprocesseurs

Nous avons aussi mesuré le gain en performances sur une machine disposant
d’un processeur quadricœurs
Ce que l’on constate ici, c’est donc généralement un gain en performances. Toutefois, on ne constate pas une division par 2 ou par 4 du temps d’exécution, en fonction du nombre de processeurs ! Ceci est dû principalement à deux facteurs : d’une part, tous les modules et toutes les opérations ne sont pas « parallélisés », mais seulement une partie et d’autre part les opérations permettant de répartir les calculs sur les différents processeurs utilisent elles mêmes de la puissance de calcul, ainsi que les opérations nécessaires pour arbitrer l’accès aux éléments partagés comme la mémoire.
Conclusion
Nous avons initié ces derniers mois un travail de fond sur l’optimisation du logiciel. Plusieurs chantiers ont été définis dans ce cadre, tout d’abord le chantier de la parallélisation, dont nous avons vu les premiers résultats. Le gain en performances est mesurable et il nous semble significatif. De plus, Cartes & Données bénéficiera à l’avenir de l’augmentation prévisible de la puissance de calcul des processeurs par la multiplication des cœurs.
Toutefois, le gain prévisible sera limité par la loi d’Amdahl, qui stipule que le gain de performances global est limité par la fraction de temps non concernée par l’amélioration : nous ne pourrons pas paralléliser intégralement le logiciel, et les parties non parallélisables limiteront le gain en performances.
Le constat effectué à l’issue de ce premier travail est double : d’une part, nous pouvons persévérer dans cette voie, car le gain est réel et mesurable. D’autre part, la portée est limitée. Pour poursuivre l’optimisation du logiciel, il y a d’autres pistes que nous mettons en œuvre et parmi celles-ci, celle de la mise en cache des résultats intermédiaires, dont nous reparlerons.
Durant ces derniers mois, d’autres problématiques ont aussi été abordées : celle tout d’abord de la fiabilité du logiciel. Nous avons corrigé au cours des derniers mois de nombreux bugs et défauts du logiciel, mais il reste à faire dans ce domaine ! »
Références
Loi de Amdahl
Gene Amdahl, « Validity of the Single Processor Approach to Achieving Large-Scale Computing Capabilities », AFIPS Conference Proceedings, (30), pp. 483-485, 1967.
>> Lire l’article correspondant sur Wikipedia